Content analysis is a method of qualitative research that has risen in popularity since the 1950s, when it began as a post-WW2 technique to analyze propaganda and mass media. This method works by translating components of text, or other forms of content, into data variables that can be placed on ordinal, nominal and interval scales for statistical analysis. But its origins actually stem all the way back to Greek antiquity and the development of the field of hermeneutics that studied early scripture. Our analysis here will take a look both at the history and applications of content analysis as a research technique, as well as provide a library of helpful references and tools for the academic research community.
“What distinguishes content analysis from most observational methods in the social sciences is that the answers to its research questions are inferred from available text.”
(Krippendorf, 2010, p. 234)
Listen to our podcast episode:
EPISODE 1: An Academic Guide to Content Analysis
Transcript
History of Content Analysis
Hermeneutics is a field addressing the interpretation of human actions and texts, or other meaningful material, that records these actions. Its origins date back to the times of Greek antiquity and the Homeric epics (Mantzavinos, 2020).
Exegesis (n) critical explanation or interpretation of text, especially scripture (origin, early 17th century)
This time period saw the formation of allegorisis, a method of nonliteral interpretation of theological texts. In the Middle Age, text interpretation introduced what was called accessus ad auctores, a standardized introduction that preceded the edition and commentaries of classical authors. This included the common 7 questions we ask of text today: who, what, why, where, how, when and by what means was the text written or published (Mantzavinos, 2020).
The field of hermeneutics continued to develop for hundreds of years. Mathias Flacius Illyricus (1520-1575), a scholar of Martin Luther and Philipp Melanchton brought the idea of using broader context to interpret text (Mayring, 2014, p. 27). In 1630, Johann Conrad Dannhauer was the first to present a systematic textbook on general hermeneutics to supplement Aristotle’s Organon in distinguishing the true meaning of a text. Johann Clauberg (1654), introduced rules of generalizing interpretation and identifying the intent of the author as a valuable piece of interpretation (Mantzavinos, 2020). Friedrich Schleiermacher (1768-1834), a contemporary of Freud, was known as the ‘father’ of hermeneutics, defined hermeneutics as the understanding of meaningful reality (not only texts). We see his position have a strong influence on psychological thought, especially originating in Germany, and the interpretation of dreams. Friedrich Ast (1778-1841) formulated the hermeneutical circle, where the interpreter brings their preconceptions to the interpretation, reads the text and then modifies their perceptions. This later morphed into the term “hermeneutical spiral” (Mayring, 2014, p. 27). We now know this spiral to exist in modern times as a debate between researching manifest and latent content (more on that below).
Up until this point, most of the past work on what we know today as content analysis took place in Germany.
But, in 1948, American political scientist, Harold Lasswell and his colleague Nathan Leites then published their seminal work “Language of Politics: Studies in Quantitative Semantics” (Janowitz, 1968) (Borg & Mohler, 1994, p. 310). It was actually around 1941 that we first see Laswell begin to use the term “content analysis” in internal and other publications although he had engaged in this type of technique during his doctoral training when studying under Charles Merriam at the University of Chicago (Franzosi, 2008) (Janowitz, 1968). In 1952, the publication of Bernard Berelson’s Content Analysis in Communication Research “codified the field of “content analysis” (Franzosi, 2008). Interestingly, Berelson was a second-generation student of Laswell’s, having studied under his associate Douglas Waples (Janowitz, 1968). But according to Kuckartz (2019), Siegfried Krakauer officially coined the term “qualitative content analysis” 1952.
“Content Analysis is a research technique for the objective, systematic, and quantitative description of manifest content of communications.”
BERELSON (Kuckartz, 2019)
Krakauer criticized both Lasswell and Berelson over the issue of manifest vs. latent content (Kuckartz, 2019).
Manifest content: content upon which it is easy for multiple authors to agree upon the analysis i.e.: a newspaper article about a train.
(Kuckartz, 2019)
Latent content: content that requires additional context from the broader view of the author’s environment or society.
Berelson’s argument is that content analysis can only be performed reliably on manifest content. When Krakauer chose the term qualitative analysis, however, he planned on the research community including broader content analysis and latent constructs (Kuckartz, 2019).
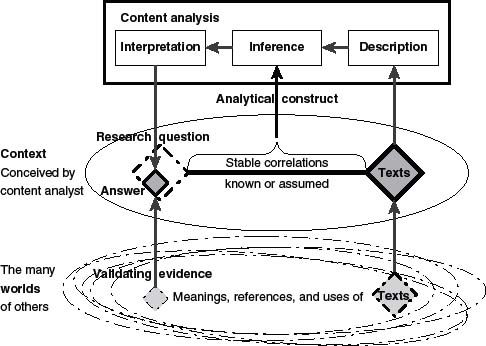
(Krippendorf, 2010, p. 235)
It is perhaps an interesting side note that Lasswell did briefly study in a cryptography lab during his graduate school (Janowitz, 1968). Given the hermeneutic traditions that have a several hundred-year history in Germany, it may be no wonder that the Lasswell/Berelson approach with quantitative coding is in opposition to researchers who focus on latent contextual analysis, many of whom are in fact located in Germany.
The issues of deciphering between manifest and latent content present an issue in the reliability of coded data. In 1969 Ole Holsti published his method to statistically analyze inter-rater reliability between multiple coders, now called the Holsti method. In the time since, several additional measures have been released including Scott’s pi (π), Cohen’s kappa (κ), and Krippendorff’s alpha (α), the later published in 1970 (Mao, 2017).
Around the same time, computer-aided content analysis was taking shape. In 1966, Philip Stone and his collaborators released one of the most promising developments in content analysis with the General Inquirer as “a system of computer programs to do content analysis objectively, automatically, and relatively painlessly” (Franzosi, 2008).
In 1990, Robert Weber’s book Basic Content Analysis released coding protocols including a 7 step method for undertaking the technique. He also introduced the concept of doing initial pilot coding and subsequent iterative stages to produce the final data (Gaur & Kumar, 2018) (Weber, 1990).
In 2002, Linda Gilbert expanded upon the issue of coding and balancing what she calls “closeness” and “distance” from the data (Rademaker et al., 2012). Several researchers have published coding styles or category libraries to add to Lasswell and Weber’s. These include Philipp Mayring who distinguishes as many as 8 different variations and works with the scale values “high self-confidence,” “medium self-confidence,” “low self-confidence,” and “self-confidence not accessible (Kuckartz, 2019) (Mayring, 2014).
At the present time there is also a significant amount of publishing on technological tools for content analysis including using natural language processing (NLP), algorithms, and machine learnings to reduce human error in coding and speed up processing. We discuss these developments in detail below.

References: (Borg, I., & Mohler, P. P. , 1994) (Franzosi, R., 2008) (Gaur, A., & Kumar, M., 2018) (Kuckartz, U., 2019 (Mantzavinos, C., 2020) (Mayring, P. ,2014)
Shareable version on Slideshare.
Content Types to Analyze
Almost anything can be analyzed for content, whether individual words, sentences or entire documents. Additionally, the field has included multi-media analysis as vast as television programs, movies, videos, pictures, and recently social media.
“What text means to somebody, what it represents, highlights and excludes, encourages or deters-all these phenomena do not reside inside a text but come to light in processes of someone’s reading, interpreting, analyzing, concluding, and in the case of content analysis, answering pertinent research questions concerning the text’s context of use.”
(Krippendorf, 2010, p.234)

Multimedia Content can also be analyzed with content analysis. The term “multimedia” can be interpreted several ways, therefore we want to clarify for the purposes of this article, that we define multimedia as containing the following elements: a) combining two or more types of media (e.g. video, sound, animation, text, and images) combined into a single package; b) provides the user an interactive experience that allows the user navigate, interact, create, and communicate; and c) the content is delivered in electronic format. This definition combines elements of the definition provided through encyclopedia.com and the University of Deleware definition as described in connection to its multimedia course.
Multimedia content analysis refers to the “computerized understanding of the semantic meanings” of content which is “embedded in multiple forms that are usually complimentary of each other” (Wang, Liu, Huang, 2000).
As you can imagine, multimedia content analysis is a multidimensional and complex undertaking, and one that can offer extraordinary insights. Content analysis at this level typically incorporates sophisticated analytical technologies. “Rich content of multimedia data, built through the synergies of the information contained in different modalities, calls for new and innovative methods for modeling, processing, mining, organizing, and indexing of this data for effective and efficient searching, retrieval, delivery, management and sharing of multimedia content” (Hanjalic, Sebe, & Chang, 2006).
Methods
Procedural steps
Weber (1990) published 7 steps for qualitative content analysis (QCA). These introduce the initial framework for establishing a pilot coding phase, coding scheme and an iterative process for revising the coding system as hypotheses are tested.
This list of Weber’s 7 steps is taken from (Gaur & Kumar, 2018).
- Definition of recording units (e.g., word, phrase, sentence, paragraph)
- Definition of initial coding scheme
- Test of coding on sub-sample of sampled text
- Assessment of accuracy and reliability of sample coding
- Revision of coding rules/coding categories definition
- Return to Step 3 until sufficient reliability is achieved
- Coding of all text
Mayring (2014) presents a different view of 7 steps of deductive category application that includes starting with the research question/hypotheses, linking the research question to a theoretical framework, establishing a research design, and then proceeding to steps of data collection and analysis. This is the type of procedure that should be documented in the methods section of a final academic paper.
One of the main tests in content analysis is frequency analysis (Mayring, 2014, p.22). This is perhaps the simplest method and includes counting the number of items related to the content that we plan to analyze. For example, counting the number of positive and negative words in a paragraph to determine the overall sentiment. Again though, latent analysis can be an issue when data collection is this simplified, depending on the type of text. Valence (ie: plus – minus) and intensity (very strong – less strong) can also be analyzed (Mayring, 2014, p. 25) Finally contingency analysis can be done to determine if text elements are contingent upon other elements, that is occur with a frequency similar to other elements, or have some other connection (Mayring, 2014, p. 25).
In designing the research project, one thing that must be defined is what level of analysis may be undertaken. For example, in a written text, are the items in that text going to be analyzed at the word, sentence or document level? In the sample codebooks we link below, you will see several options for coding down to the word-level.
Coding
Coding, or tagging, is the process of assigning elements of an analyzed text to the construct to be measured. Franzosi (2008) says that coded statements can have two basic categories: direction (sentiment) and standards (topic/theme). According to Franzosi (2008) “the categories of standard most frequenly used are ‘strength-weakness’ and ‘morality-immorality’.
There are three coding system approaches:
- Deductive: creating the codebook prior to coding
- Inductive: developing the codebook while coding, as the data informs the researcher
- Hybrid: A blended approach, starting with a basic codebook and allowing, if not expecting, changes to the codebook
Mayring (2014) describes “comprehensive category systems (so-called “dictionaries”), which are supposed to include all aspects of a text and form the basis for a computer count of
language material.

Here are a few resource to assist with your development of a codebook:
Harvard site collecting General Inquirer tag categories such as the Lasswell Value Dictionary and the Harvard IV-4 dictionary. This site also details the history of the development of the General Inquirer and its creator Philip Stone.
SentiWordNet – is a lexical resource on github for sentiment analysis of opinion mining. It has several human coded lexicons available.
Inter-Rater Reliability
Inter-rater or inter-coder reliability is a significant issue in ensuring that the meaning researchers assign to content is valid, before analysis use this data in statistical procedures. Issues arise when context information is not consistent between raters or even when the rater’s perceptions/worldview/ or personal histories color their perceptions. This is why code books are helpful to ensure that all researchers in a study who are rating text are working from the same understanding of how data will be coded.
We’ve already discussed several of the statistical reliability techniques that have been developed to test for inter-rated reliability. It is perhaps concerning that Gaur & Kumar (2018) in their review of 25 years of international business academic publishing, found that less than 50% of papers that used the content analysis technique also published their reliability measures.
University of Pennsylvania archives provide a detailed overview of computing the Krippendorf’s alpha reliability coefficient.
Resources for computing inter-coder reliability (ICR) in Statistical software:
- Instructions for using the KALPHA macro in SPSS. You can download the KALPHA macro from Robert Hayes’ site.
- MatLab functions for performing Krippendorf’s alpha.
- The ALPHA site at Essex University has links to scripts from several other researchers.
R packages to produce reliability
- irr package includes Krippendorfs alpha (kripp.alpha), Cohen’s kappa (N.cohen,kappa; N2.cohen,kappa)
- tidycomm package allows use of the test_icr function to test inter-coder reliability. Adjust holsti, kripp_alpha, cohens_kappa TRUE/FALSE.
Python scripts can also be found on github.
Example
Cynthia Chew, & Gunther Eysenbach. (2010). Pandemics in the age of Twitter: content analysis of Tweets during the 2009 H1N1 outbreak. PLoS ONE, 11, e14118. https://doi-org.login.library.coastal.edu:8443/10.1371/journal.pone.0014118
Analyzed 2 million Twitter posts between May 1 and December 31, 2009 for posts containing words “swine flu,” “swineflu,” and/or “H1N1.” They samples 5395 tweets randomly across 9 days, 4 weeks apart and coded using a tri-axial coding scheme (content, qualifiers, links). The researchers used a machine-coding system to compare coding reliability with human coding.
The study details examples of their coding categories and framework. In the codebook they include specific rules for each coding area. For example the content area is: detailed description, examples of emoticons/slang that might be used, and example messages. Whereas the coding for the link category may include items that are mainstream or local news vs. a news blog/food/niche news.
The methods section of this paper details their process as well especially iterative efforts to sample and update the coding scheme, the percentage of coding done between humans and computer-assisted, as well as their kappa reliability values. The researchers continually computed their kappa values iteratively with each version of the codebook until the final kappa value was > .7.
Their results primarily show frequency results including that in the H1N1 pandemic, news and information were the most commonly tweeted material. In comparing the content, they found the greatest areas of concern were protective behaviors when the threat of the outbreak increased. This is an interesting example of including latent analysis as well since they bring the context of other items going on during the timeline of analysis.
Computer-based tools for qualitative content analysis
Computer data analysis software for qualitative research (CAQDAS) began to be widely available widely in the late 1990s. (Rademaker et al., 2012) This field has evolved significantly over time and continues to see advancements in more sophisticated machine learning and artificial intelligence technologies. We present a list of academic research tools below that have been referenced in our own research. In addition to these tools, there is an entire market of commercial-grade services that are for sale to businesses.
| Program | Description | Review Guide | References | |
| ATLAS.ti | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) | |
 | HyperRESEARCH | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) |
 | MAXQDA | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) |
 | NVivo (NUD*IST, past version) | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) |
 | QDA Miner | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) |
| Transana | Commercial Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) | |
| Open Code | Open Source | N/A | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) | |
| Dedoose (Qualrus, past version) | Web-Based Software Program | Review Guide | (Corbin & Strauss, 2015) (Creswell & Poth, 2018) | |
| QCAMap | Open Source | N/A | Managed by Prof. Philipp Mayring and Dr. Thomas Fenzl | |
| PC-ACE | Open Source | N/A | Managed by Prof. Robert Franzosi of Emory University. |
This chart is not meant to be a ranking list or comparative chart, but to highlight the current, most popular Computer Software Programs as noted in today’s leading Qualitative Research textbooks. Computer programs can support the facilitation of qualitative data analysis, and each researcher must determine the best tools to meet researcher needs.
Natural Language Processing (NLP) is an important component of content analysis. It is a type of software that can utilize computers to automatically interpret the quantification of meaning of texts.
- Apache OpenNLP
- PC-ACE
- R – NLP packages
- CRAN project– R packages, resources and references for NLP
- LSA – Latent Semantic Analysis
- ReadMe2
- 5 Packages for Text Analysis with R (Rul, 2019)
Social Media analysis can also be called “opinion mining” or “sentiment analysis” as it attempts to turn opinions, feelings, beliefs, emotions, and intent expressed in social media messages into computational treatments (GONZÁLEZ-BAILÓN & PALTOGLOU, 2015). This content type often merges text and multimedia content.
There are dozens of commercial-grade Social Media Analysis tools on the market that are used by businesses to fetch and analyze social media content and even analyze other forms of content analysis such as emails, survey data, ratings and reviews, forums posts, etc. Many provide comprehensive descriptive statistics such as frequencies and percentages, but few provide the level of statistical analysis that we may be used to in academic research.
NodeXL is an excel plugin for social network analysis. It supports text, sentiment, time series analysis and statistical calculations such as network metrics (Density/Modularity/etc.), vertex metrics (Degree/Indegree/Outdegree), advanced vertex metrics (Betweenness/Closeness/ Eigenvector/PageRank/etc.) and Group vertices by cluster or attributes. It also offers network visualizations to see relationships between items.
Textbook Resources
This blog is being published as part of a project in BUS-702: Spring 2020 Qualitative Research Methods with Professor Brianna Barker Caza at UNC Greensboro. In review of the required and recommended textbook/book readings in our current course, the following sections of these books were helpful to us in understanding Content Analysis.

Charmaz, K. (2006). Constructing Grounded Theory. ISBN 0857029142
- Chapter 3, Page 42: Coding in Grounded Theory Practice; coding practices (e.g. line by line, word by word, or incident by incident)
Creswell, J. (1998). Qualitative inquiry and research design: Choosing among 5 traditions Thousand Oaks, CA: Sage. ISBN 1506330207
A number of tables and figures related to “Content Analysis” topics were helpful, particularly:
- Page 186, Figure 8.1: The Data Analysis Spiral
- Page 187, Table 8.3: The Data Analysis Spiral Activities, Strategies, and Outcomes
- Page 191, Figure 8.2: Example of Coding Procedures for Theme “Fostering Relationships”
- Page 192, Table 8.4: Example of Codebook Entry for Theme “Fostering Relationships”
- Chapter 8, Pages 207-220: Computer Use in Qualitative Data Analysis with subsections focused on: advantages and disadvantages; Sampling of Features; Use of Computer Software Programs with the Five Approaches; Templates for Coding.
Lofland, J., Snow, L. Anderson, L., Lofland. L. (2006). Analyzing Social Settings: A Guide to Qualitative Observation and Analysis. ISBN 0534528619
- Part III: Analyzing Data: specifically, Chapter 9, Developing Analysis, beginning on page 195. Page 200-209 focus on Coding Strategies.
Strauss & Corbin (2015). Basics of Qualitative Research., Fourth Edition. ISBN 1412997461
Of the required or recommended books for this course, we found this particular text to provide the most robust resources regarding “Content Analysis” topics.
- Page 203 very useful intro to computer programs.
- Chapter 4, Prelude to Analysis, relevant subsections include: Page 64, The Nature of Qualitative Analysis; Page 70, Delineating Context Is an Important Aspect to Analysis; Page 71, Microanalysis; Page 76, The Logic of Grounded Theory Analysis.
- Chapter 5, Strategies for Qualitative Data Analysis, beginning page 85.
- Chapter 11, The Use of Computer Programs in Qualitative Data Analysis, beginning page 203. Particularly informative in review of several primary QDA Software programs. See Table 11.1, pages 206-210.
- Chapter 12, Open Coding, beginning page 215.
- Chapter 14, Analyzing Data for Context, beginning page 268.
Weiss, R. (1994). Learning from Strangers: The Art and Method of Qualitative Interview Studies. ISBN 0029346258
- Chapter 6, pages 151-167, Analysis of Data, provides a broad overview of analysis. Page 152 begins a section to address four (4) different approaches to analysis and coding strategies (e.g., issue focused, case focused).
- Appendix E, Pages 219-222, Qualitative Coding of Qualitative Interview Material, provides a segment of a codebook and scenario, to provide a concrete example to the reader.
Other Resources
💻In addition to our references below for the content of this article, we have completed a reference library in Zotero that is open access. This source may be helpful if you are looking for method citations for an upcoming research article.
💻 To discuss the content in this article, we have already created an open Hypothes.is group called “Content Analysis” to discuss the elements and references included herein.
💻Another reference source may be this Annotated bibliography of Content Analysis References from Colorado State.
💻 The CAQDAS Networking Project was formally established in 1994 and provides information, advice, training and support for anyone undertaking qualitative or mixed methods analysis using dedicated Computer Assisted Qualitative Data Analysis (CAQDAS) packages.
💻 The Qualitative Report is a peer-reviewed, on-line monthly journal devoted to writing and discussion of and about qualitative, critical, action, and collaborative inquiry and research. The Qualitative Report, published by Nova Southeastern University, is the oldest multidisciplinary qualitative research journal in the world, serves as a forum and sounding board for researchers, scholars, practitioners, and other reflective-minded individuals who are passionate about ideas, methods, and analyses permeating qualitative, action, collaborative, and critical study.
💻 Gary King, PhD is the Albert J. Weatherhead III University Professor at Harvard University — one of 25 with Harvard’s most distinguished faculty title — and Director of the Institute for Quantitative Social Science. His site has a plethora of information including research references, software, and data for content analysis. He is also the co-chair of SocialScienceOne, a partnership between academics and Facebook to analyze social media’s impact on democracy and elections. If you plan to engage in content analysis of Facebook content, you may wish to follow this organization and its research opportunities.
💻Philipp Mayring manages the Quantitative Content Analysis site. This includes an extensive library of his published work on content analysis methods, access to QCAmap, and research awards.
References
Belotto, M. J. (2018). Data Analysis Methods for Qualitative Research: Managing the Challenges of Coding, Interrater Reliability, and Thematic Analysis. Revista Brasileira de Enfermagem, 71, 2622–2633.
Borg, I., & Mohler, P. P. (1994). Trends and Perspectives in Empirical Social Research. De Gruyter, Inc. http://ebookcentral.proquest.com/lib/uncg/detail.action?docID=3042018
Charmaz, K. (2014). Constructing grounded theory (2nd edition). Sage.
Cynthia Chew, & Gunther Eysenbach. (2010). Pandemics in the age of Twitter: content analysis of Tweets during the 2009 H1N1 outbreak. PLoS ONE, 11, e14118. https://doi-org.login.library.coastal.edu:8443/10.1371/journal.pone.0014118
Corbin, J. M., & Strauss, A. L. (2015). Basics of qualitative research: Techniques and procedures for developing grounded theory (Fourth edition). SAGE.
Feinerer, I., Hornik, K., & Meyer, D. (2008). Text Mining Infrastructure in R. Journal of Statistical Software, 25(1), 1–54. https://doi.org/10.18637/jss.v025.i05
Franzosi, R. (2008). Content Analysis (Vol. 1–4). SAGE Publications Ltd. https://doi.org/10.4135/9781446271308
Gaur, A., & Kumar, M. (2018). A systematic approach to conducting review studies: An assessment of content analysis in 25years of IB research. Journal of World Business, 53(2), 280–289. https://doi.org/10.1016/j.jwb.2017.11.003
Ghoneim, S. (2019, April 16). 5 Types of bias & how to eliminate them in your machine learning project. Medium. https://towardsdatascience.com/5-types-of-bias-how-to-eliminate-them-in-your-machine-learning-project-75959af9d3a0
GONZÁLEZ-BAILÓN, S., & PALTOGLOU, G. (2015). Signals of Public Opinion in Online Communication: A Comparison of Methods and Data Sources. The Annals of the American Academy of Political and Social Science, 659, 95–107. JSTOR.
Hanjalic, A., Sebe, N., & Chang, E. (2006, January). Multimedia content analysis, management and retrieval: Trends and challenges. In Multimedia Content Analysis, Management, and Retrieval 2006 (Vol. 6073, p. 607301). International Society for Optics and Photonics.
Intercoder Reliability Techniques: Holsti Method. (2017). In M. Allen, The SAGE Encyclopedia of Communication Research Methods. SAGE Publications, Inc. https://doi.org/10.4135/9781483381411.n258
Janowitz, M. (1968). Harold D. Lasswell’s Contribution to Content Analysis. The Public Opinion Quarterly, 32(4), 646–653. JSTOR.
Krippendorff, K. (2010). Content analysis. In N. J. Salkind (Ed.), Encyclopedia of research design (pp. 234-238). Thousand Oaks, CA: SAGE Publications, Inc. doi: 10.4135/9781412961288.n73
Kuckartz, U. (2019). Qualitative Content Analysis: From Kracauer’s Beginnings to Today’s Challenges. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 20(3), Article 3. https://doi.org/10.17169/fqs-20.3.3370
Lofland, J., & Lofland, J. (Eds.). (2006). Analyzing social settings: A guide to qualitative observation and analysis (4th ed). Wadsworth/Thomson Learning.
Mao, Y. (2017). Intercoder reliability techniques: holsti method. In M. Allen (Ed.), The sage encyclopedia of communication research methods (Vol. 2, pp. 741-743). Thousand Oaks, CA: SAGE Publications, Inc doi: 10.4135/9781483381411.n258
Mayring, P. (2014). Qualitative content analysis: Theoretical foundation, basic procedures and software solution. https://www.ssoar.info/ssoar/handle/document/39517
Rademaker, L. L., Grace, E. J., & Curda, S. K. (2012). Using Computer-Assisted Qualitative Data Analysis Software (CAQDAS) to Re-Examine Traditionally Analyzed Data: Expanding our Understanding of the Data and of Ourselves as Scholars. Qualitative Report, 17. https://files.eric.ed.gov/fulltext/EJ978742.pdf
Short, J. C., & Palmer, T. B. (2007). The Application of DICTION to Content Analysis Research in Strategic Management: Organizational Research Methods. https://doi.org/10.1177/1094428107304534
Vaismoradi, M., & Snelgrove, S. (2019). Theme in Qualitative Content Analysis and Thematic Analysis. Forum: Qualitative Social Research, 20(3), 1.
Wang, Y., Liu, Z., & Huang, J. C. (2000). Multimedia content analysis-using both audio and visual clues. IEEE signal processing magazine, 17(6), 12-36.
Weber, R. (1990). Content Classification and Interpretation. In Basic Content Analysis (pp. 16–40). SAGE Publications, Inc. https://doi.org/10.4135/9781412983488.n2
Weiss, R. S. (1994). Learning from strangers: The art and method of qualitative interview studies. Free Press ; Maxwell Macmillan Canada ; Maxwell Macmillan International.
Zucco, C., Calabrese, B., Agapito, G., Guzzi, P. H., & Cannataro, M. (2020). Sentiment analysis for mining texts and social networks data: Methods and tools. WIREs Data Mining and Knowledge Discovery, 10(1), e1333. https://doi.org/10.1002/widm.1333
Meet the Authors


La lecture de votre article a été très agréable. Jilleen Rufe Given
LikeLike
Merci!
LikeLike